 Eseandre Mordi
Eseandre Mordi

⬤ New METR evaluation results reveal Claude Opus 4.5 reaches a 50% time horizon of 4 hours and 49 minutes on long-horizon software engineering tasks, meaning it successfully completes tasks of that length about half the time. The benchmark data compares Opus 4.5 directly with GPT-5.1-Codex-Max across increasing task durations.
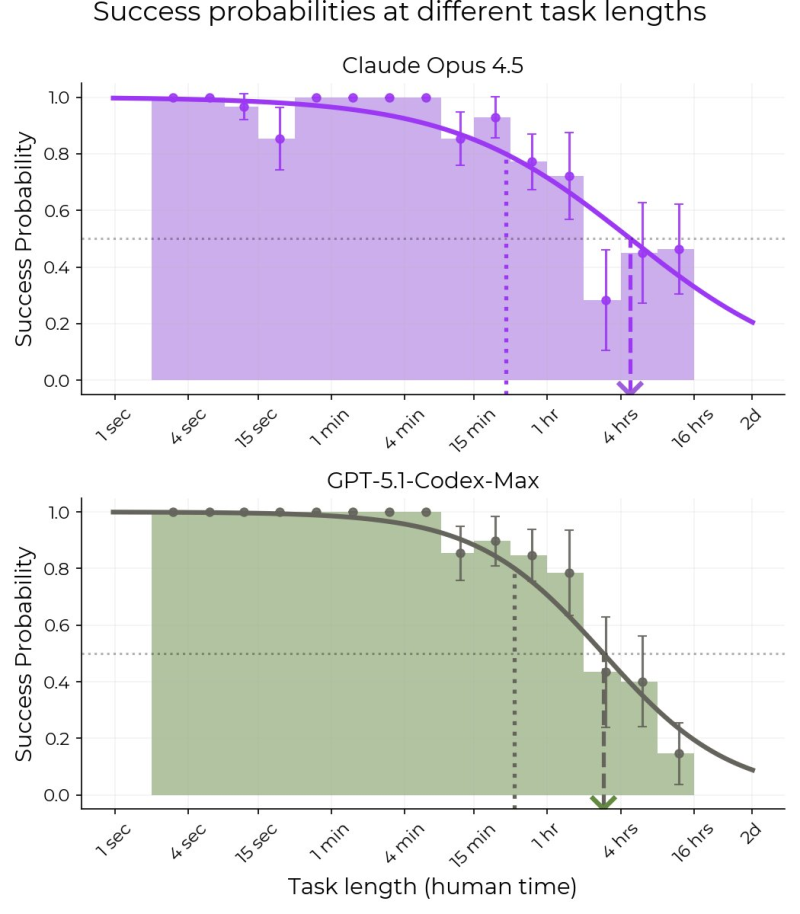
⬤ Claude Opus 4.5 shows very high success rates on short tasks lasting seconds to minutes, with performance gradually declining as tasks extend into hours. The model crosses the 50% success threshold just under five hours, marking one of the longest median task durations observed in the benchmark and indicating a high capability ceiling for complex software engineering work.
⬤ Despite the impressive 4-hour 49-minute median, Opus 4.5's 80% reliability horizon drops to just 27 minutes, similar to previous models and below GPT-5.1-Codex-Max's 32-minute mark. This large gap between the 50% and 80% thresholds reflects inconsistent performance—the model occasionally succeeds on very long tasks but can't do so reliably.

⬤ The results highlight a key trade-off in advanced AI systems: Claude Opus 4.5 can handle unusually long tasks part of the time, but its much shorter high-reliability horizon shows it makes more errors as task complexity increases. These findings emphasize why evaluating AI models now requires looking at the full success curve rather than single metrics, as frontier progress often involves meaningful trade-offs between capability reach and consistency.
 Eseandre Mordi
Eseandre Mordi


