 Saad Ullah
Saad Ullah

● AI researcher Andrew Trask recently published a Substack analysis warning that GPU demand forecasts might be massively overblown. His core argument? Most projected growth assumes AI will keep burning through chips at current rates — but software efficiency is improving so fast that hardware needs could plateau much sooner than expected.
● Early AI models were incredibly inefficient, requiring far more processing power than they theoretically needed. As researchers optimize these systems, they're finding that much of the computational load was unnecessary all along. That means demand projections based on today's wasteful models could be wildly off.
● There's a dangerous gap between what AI engineers understand and what business leaders believe. Executives and investors making trillion-dollar bets on AI infrastructure often can't distinguish between essential compute needs and the bloat that's being rapidly eliminated. If efficiency keeps improving at its current pace, hardware manufacturers and their investors could face a serious reality check.
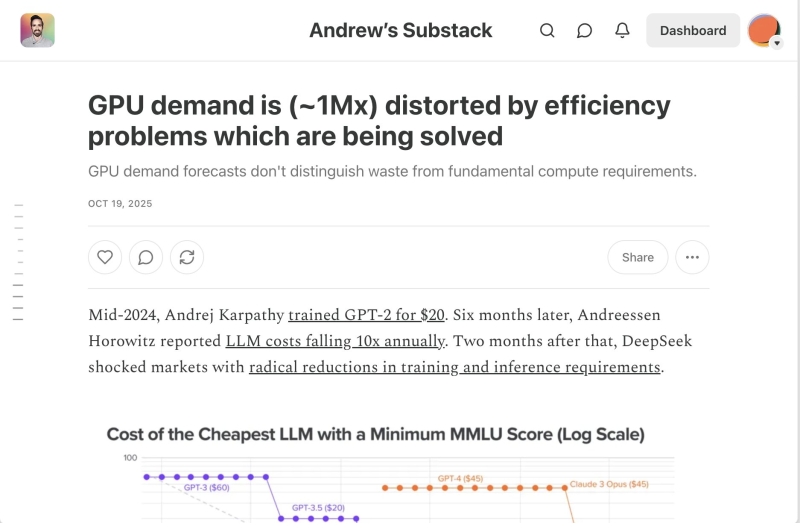
● Recent developments support this view. In mid-2024, Andrej Karpathy trained GPT-2 for just $20. Shortly after, Andreessen Horowitz reported that LLM training costs were dropping 10× annually. Then DeepSeek introduced breakthroughs that slashed both training and inference requirements across the board. "Version X-1 was 90% waste. Version X-2 was 99% waste," Trask notes, highlighting how each generation eliminates more inefficiency.
● The math is striking: software optimization accounts for roughly 86% of efficiency gains, with hardware improvements contributing only marginally. If this continues, global GPU consumption might peak well before 2030 — upending the massive growth projections that currently drive the semiconductor industry.
 Saad Ullah
Saad Ullah


