 Peter Smith
Peter Smith

A recently resurfaced OpenAI research paper is making waves in the AI community for its bold attempt to crack open the black box of neural networks. While most companies chase bigger and more powerful models, this work tackles an equally important challenge: understanding what's really happening inside these systems. The research showcases a radically different way to build transformers—one that prioritizes sparsity, transparency, and visibility into how AI makes decisions.
Breaking Down the Sparse Model Architecture
The paper introduces a new class of weight-sparse transformer models designed specifically to expose the internal "circuits" that emerge when language models learn.
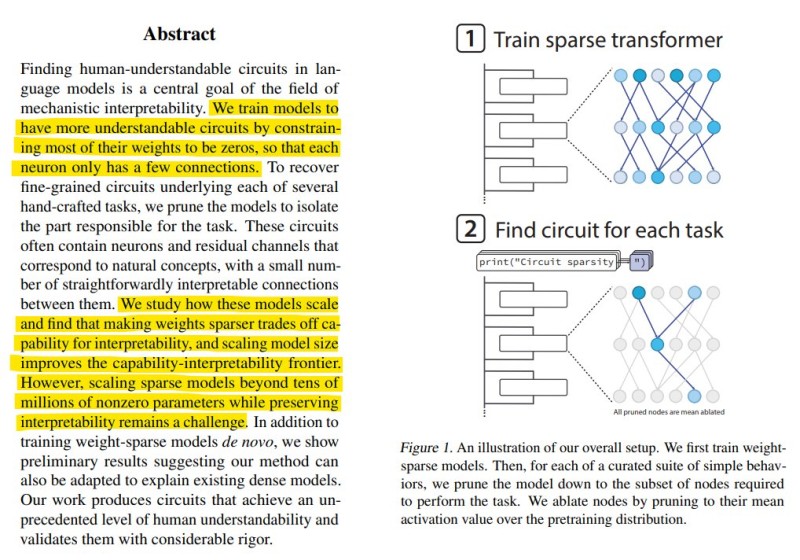
Unlike traditional dense networks where billions of parameters interact in complex, tangled ways, these sparse models force most connections to zero. Each neuron only links to a handful of others, creating an intentionally constrained architecture that's far simpler to decode.
How the Two-Stage Process Works
Here's how it works: researchers first train a sparse transformer with minimal connections between neurons. Then, for each specific task they want to study, they prune away everything except the exact neurons responsible for that behavior. What's left is a dramatically streamlined circuit—about 10 times smaller than what you'd find in a standard dense transformer—that still performs the task just as well. This two-stage process gives scientists an unprecedented window into how models build representations, route information, and combine simple features into complex concepts.
Key Findings:
- Sparse transformers achieve comparable performance on specific tasks while using roughly 10× fewer active parameters than dense models, making their internal operations far more traceable and understandable
- The research successfully recovers fine-grained computational circuits for various language tasks and maps them to natural concepts with clear, traceable connections throughout the network
- While sparse models offer dramatically improved interpretability, they face a fundamental tradeoff—they're significantly less capable than cutting-edge systems like GPT-5, Claude, or Gemini for general-purpose tasks
- Scaling sparse architectures beyond tens of millions of active parameters remains a major technical challenge that limits their practical deployment in production environments
The Capability vs. Interpretability Tradeoff
The tradeoff is real and significant. These sparse models are much easier to interpret, but they can't match the raw power of today's frontier AI systems. The paper acknowledges this directly: sparsifying weights boosts interpretability but tanks overall capability. Scaling these architectures to hundreds of millions or billions of parameters remains an unsolved problem.
Implications for AI Safety and Future Development
Still, the implications are huge. For the first time, researchers can actually see how language models form their internal logic, rather than just guessing based on inputs and outputs. This kind of mechanistic clarity is nearly impossible with full-scale models that have billions of densely interconnected parameters.

As AI systems become more embedded in critical decisions—from healthcare to finance to public policy—this research offers a path toward building systems we can actually trust and audit. By revealing the real circuits behind model behavior, OpenAI's work could shape future safety tools, inform regulatory standards, and deepen our scientific understanding of how intelligence emerges from computation. This might just be a turning point in how we study and design the next generation of AI systems.
 Peter Smith
Peter Smith


