 Eseandre Mordi
Eseandre Mordi

⬤ HuggingPapers recently highlighted GTR-Turbo, a reinforcement learning innovation that's catching attention across AI infrastructure circles. The technique works by combining multiple training checkpoints into one unified teacher model. Instead of depending on costly external systems like GPT or Gemini for guidance, GTR-Turbo generates teaching signals internally from this merged checkpoint—a shift that fundamentally changes the economics of model training.
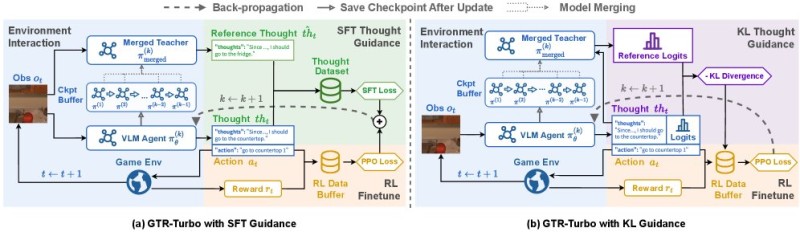
⬤ The results speak for themselves: accuracy jumps between 10% and 30%, training time drops by half, and compute costs fall around 60%. The system uses its merged teacher model as a built-in reference during reinforcement learning, helping the training agent make smarter decisions while working through tasks. This kind of efficiency matters in an industry where GPU-intensive workflows dominate AI development.
⬤ What makes this approach particularly significant is how it sidesteps the need for repeated calls to large external models during training. By pulling teacher guidance straight from the merged checkpoint, developers eliminate ongoing API costs and streamline their entire reinforcement learning process. That translates to faster experimentation cycles and lower barriers to entry for teams working on vision-language systems.

⬤ GTR-Turbo represents more than just incremental improvement—it's the kind of efficiency leap that could reshape development strategies across the AI sector. When you can deliver better accuracy while spending less time and money, it changes how organizations think about scaling models and allocating infrastructure resources. For an industry built on compute-heavy workloads, those economics matter.
 Eseandre Mordi
Eseandre Mordi


