 Saad Ullah
Saad Ullah

● In performance testing shared by Ahmad, the RTX Pro 6000 (Blackwell architecture) drastically outperformed the DGX Spark (GB10) when running large language models. The tests measured end-to-end latency using 2k-token inputs and 2k-token outputs (Batch 1), and the results were striking: the RTX Pro 6000 completed tasks six to seven times faster.
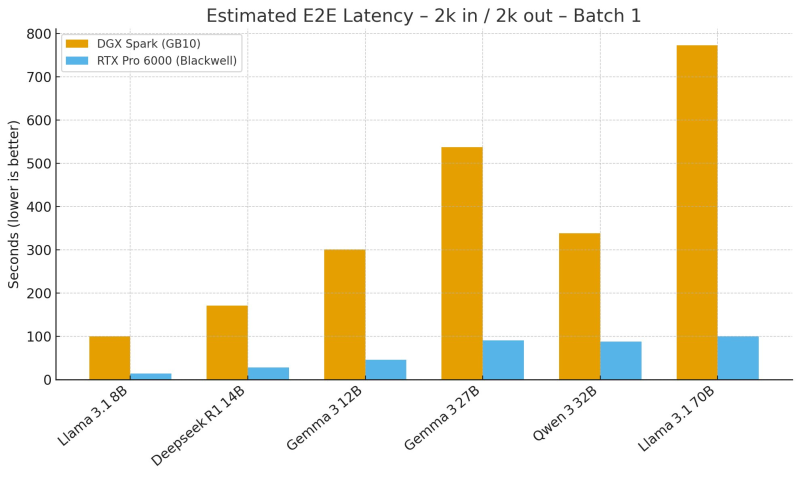
● These findings reveal something important about modern AI workloads. It's not just about raw compute anymore — memory bandwidth has become the bottleneck. The RTX Pro 6000 offers 1792 GB/s memory bandwidth compared to the DGX Spark's 273 GB/s. As an analyst put it, "LLM inference is memory-bound," meaning GPU memory speed now matters more than core count for real-world performance. This could push data centers and AI labs to rethink their hardware strategies.
● The cost-performance numbers tell an even more compelling story. Despite costing only about 1.8× more, the RTX Pro 6000 runs inference 6–7× faster. In the tests, DGX Spark took 100 seconds to process a Llama 3.1 8B query versus just 14 seconds on the RTX Pro 6000. For the larger Llama 3.1 70B model, Spark needed 13 minutes while the RTX finished in 100 seconds — a massive efficiency gap that could reshape AI infrastructure economics.
● What makes this interesting is the broader implication: workstation-class GPUs like the RTX Pro 6000 might start replacing dedicated data-center hardware for certain inference tasks. With superior memory throughput and optimized architecture, the RTX Pro 6000 doesn't just reduce latency — it offers developers a practical, cost-efficient option for deploying real-time LLMs without needing enterprise-grade server infrastructure.
 Saad Ullah
Saad Ullah


