 Marina Lyubimova
Marina Lyubimova

⬤ A top Chinese AI research team has published groundbreaking work on what they're calling the Agentic Learning Ecosystem (ALE), paired with a reinforcement-learning framework named ROME. The research makes a bold claim: today's AI agent infrastructure has serious structural limitations. Their proposed solution? A complete training ecosystem built around closed-loop task execution, real-time feedback, and nonstop learning. The team backed up their claims with performance tests across multiple AI coding and task-execution benchmarks.
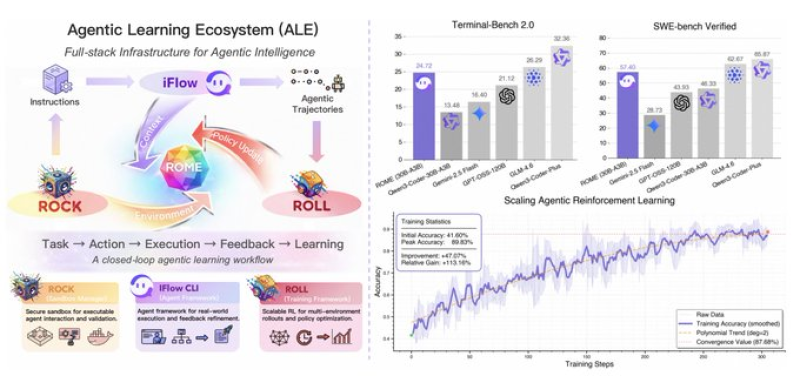
⬤ The system integrates several core modules—ROCK, iFlow, and ROLL—that work together to handle task execution, environment interaction, policy updates, and multi-round training cycles. Here's how it works: user instructions flow into task actions, which generate learning feedback through what the researchers call "agentic reinforcement learning." The benchmark results are impressive. Tests on Terminal-Bench 2.0 and SWE-bench Verified showed measurable improvements across training steps, with one striking example: accuracy jumped from 41.97% to 67.21% using the agentic training approach.

⬤ What sets ALE and ROME apart is their focus on real-world applications rather than just academic exercises. The system runs on a continuous "policy update loop" where agent behavior gets refined as interaction data feeds back into the system. Performance tracking revealed rising accuracy throughout training, with convergence reaching 87.86% after extended reinforcement cycles. The lab sees this architecture as a stepping stone toward truly autonomous AI systems that learn from experience.
 Marina Lyubimova
Marina Lyubimova


