 Saad Ullah
Saad Ullah

The race to power advanced AI models is intensifying, and Google's Tensor Processing Units are suddenly in the spotlight. These specialized AI accelerators are moving center stage following Anthropic's landmark partnership to secure up to one million TPUs, representing over a gigawatt of computing power. This deal signals that TPUs are becoming genuine alternatives to GPUs for large-scale model training and inference.
Inside Google's TPU Architecture
Google's TPU achieves efficiency through intelligent design, as detailed by TuringPost. At its core sits the Matrix Multiply Unit (MXU), a 256×256 systolic array handling the massive matrix multiplications that power neural networks.
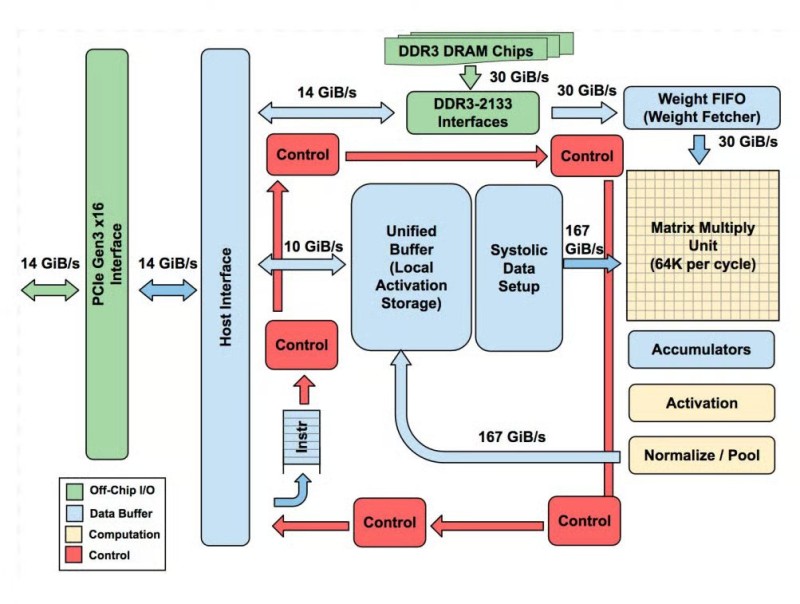
The Unified Buffer feeds data at 167 GiB/s while DDR3 DRAM interfaces add another 30 GiB/s from external memory. The Weight FIFO streams model weights efficiently, and specialized units handle post-multiplication processing on-chip, reducing memory transfers. This tightly integrated design minimizes off-chip data movement, the biggest bottleneck in neural network computation.
From Prototype to Powerhouse: The Evolution of TPUs
Google introduced TPUs in 2015 to accelerate Search, Translate, and YouTube recommendations. The latest generation, TPU v7 "Ironwood," marks a major leap forward. Designed for inference efficiency with liquid cooling, it can be configured in 256-chip pods or massive 9,216-chip superpods, achieving industry-leading performance per watt. Google has transformed the TPU into a neural network co-processor optimized for sustained throughput.
Anthropic's Strategic Bet on TPUs
Anthropic's commitment to up to one million TPUs reflects where AI infrastructure is heading. The company behind Claude language models is betting that Google's custom chips will deliver superior efficiency, reliability, and integration with frameworks like TensorFlow XLA and JAX. Compared to GPUs, TPUs offer lower operating costs through better performance per watt, tighter integration with Google Cloud's AI ecosystem, and more predictable scaling across distributed systems. This translates to faster training and cheaper inference at industrial scale.
TPUs vs. GPUs: A Shifting Competitive Landscape
While Nvidia GPUs have dominated AI hardware for nearly a decade, TPUs now offer a specialized alternative focused exclusively on neural network performance. TPUs are purpose-built for matrix operations with minimal overhead and predictable data flow, making them ideal for transformer-based models. As AI models grow and energy costs climb, the TPU's ability to maintain massive throughput with lower energy consumption could reshape how large-scale AI systems are built.
 Saad Ullah
Saad Ullah


