 Saad Ullah
Saad Ullah

⬤ The AI community is buzzing after a GPT-5-based agent posted impressive results on OSWorld, a benchmark that tests whether AI can actually get things done on a real computer. The system, which combines GPT-5 with Opus 4.5, hit a 72.6% success rate and currently sits at the top of the leaderboard among similar agent systems.
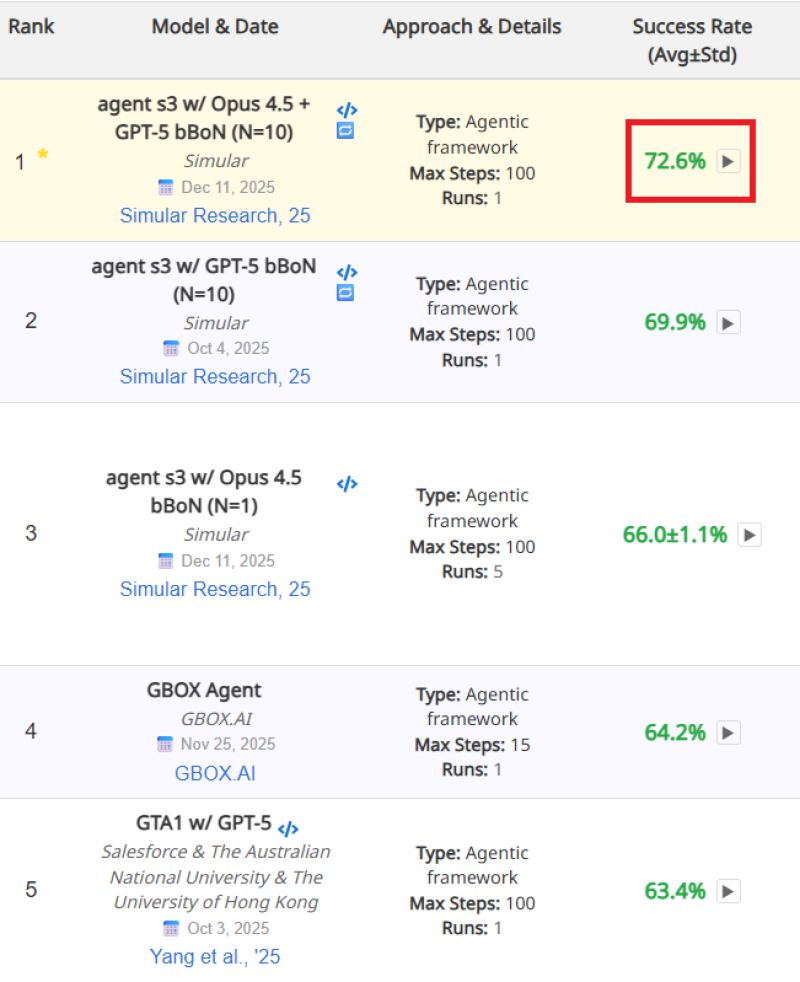
⬤ OSWorld isn't about answering trivia or solving puzzles—it's about completing actual tasks. The agents need to navigate operating systems, manage files, work with user interfaces, and use everyday software tools. The GPT-5 and Opus 4.5 combo outpaced other frameworks, including earlier GPT-5 versions and competing models that couldn't break 70%. These results were published in December 2025, making them among the freshest benchmarks for computer-using AI.
⬤ What makes this interesting is that 72.6% is being called roughly human-level performance for this specific task set. The gap between AI agents and actual human users doing routine desktop work is getting smaller. These systems aren't fully autonomous yet, but they're proving increasingly capable at handling multi-step workflows across real applications—the kind of software people use every day.

⬤ This matters beyond tech circles. Better agent reliability opens doors for enterprise automation, productivity tools, and large-scale AI deployment. As benchmarks like OSWorld show rising scores, we're likely to see faster adoption of computer-using agents in everyday workflows, driving demand for AI infrastructure and automation tools across industries.
 Saad Ullah
Saad Ullah


