 Victoria Bazir
Victoria Bazir

⬤ Researchers have unveiled AR3D-R1, breaking new ground as the first text-to-3D model powered by reinforcement learning. The system extends RL techniques from text and image generation into 3D space, using a step-by-step pipeline that transforms rough 3D shapes into detailed, textured objects through structured reasoning and reward-based optimization.
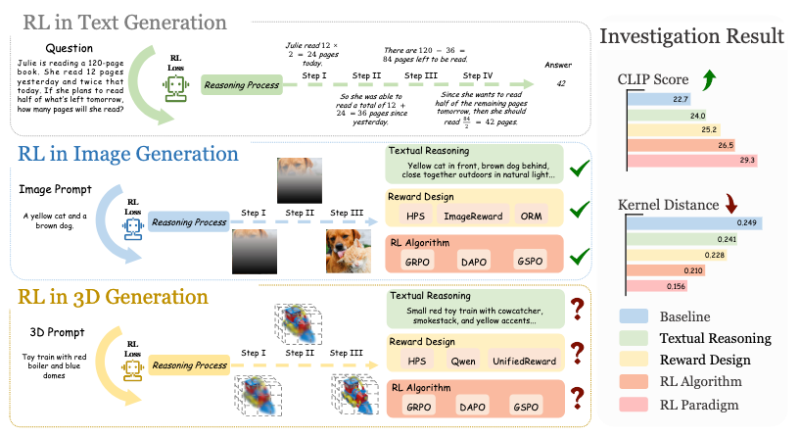
⬤ AR3D-R1 applies RL-based reasoning at each generation stage, moving beyond traditional supervised learning approaches. The model leverages textual reasoning, custom reward systems, and specialized RL algorithms to create 3D assets that closely match text prompts. This marks a shift from earlier methods that couldn't effectively optimize the complex relationship between descriptions and 3D outputs.
⬤ Alongside the model comes MME-3DR, the first benchmark designed specifically for measuring RL performance in 3D generation. Testing shows RL-enhanced models achieve higher CLIP Scores and lower kernel distance values compared to baselines, proving better prompt alignment and more consistent outputs. These metrics confirm that reinforcement learning delivers real improvements when tackling 3D generation challenges.

⬤ AR3D-R1's launch signals a major expansion of RL applications into complex, multi-dimensional generation tasks. By combining reasoning processes, reward mechanisms, and multi-stage refinement, the model tackles long-standing problems in text-to-3D conversion. Both AR3D-R1 and MME-3DR now serve as key references for researchers pushing RL-driven 3D content creation forward.
 Victoria Bazir
Victoria Bazir


