 Marina Lyubimova
Marina Lyubimova

⬤ Recent benchmark results show something remarkable happening in AI development—models are getting way better at sticking with complex tasks for extended periods. The latest data tracks how long different AI systems can work before hitting a 50% chance of failure, and the improvement curve is getting steeper. Early models like GPT-3 could barely handle tasks lasting more than a few minutes. Fast forward to 2025, and we're seeing AI systems maintain effectiveness for hours on end.
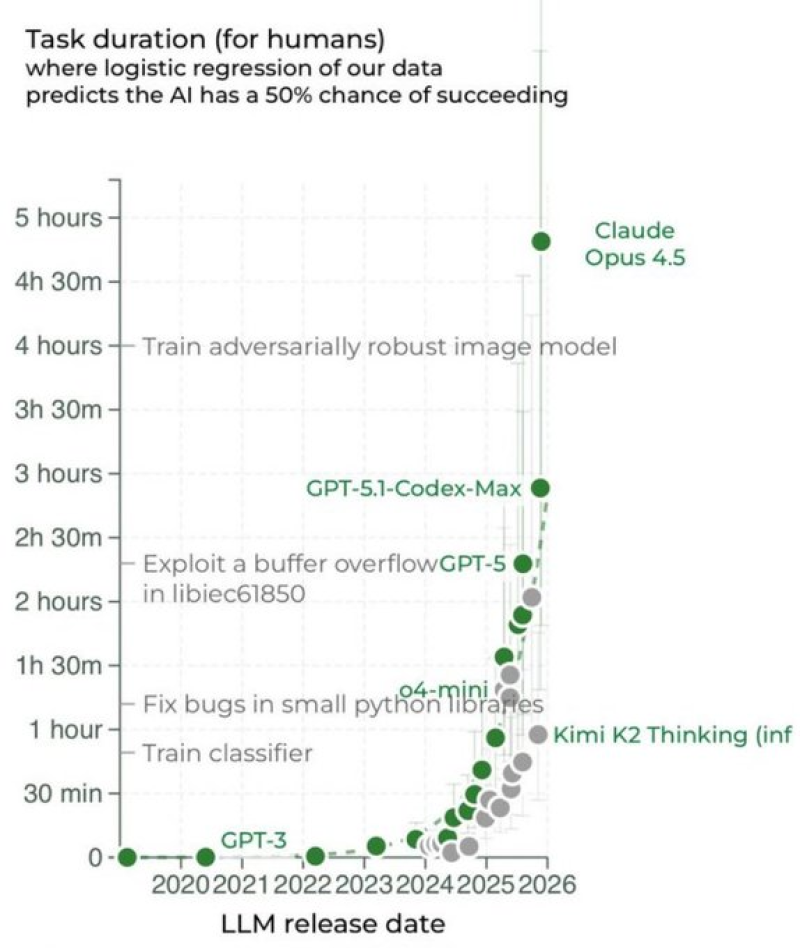
⬤ Claude Opus 4.5 sits at the top of this new data, managing close to five hours of sustained performance before success rates drop to 50%. That's a huge jump from earlier versions and competing models. What makes this even more impressive is the type of work these systems are handling—we're talking about debugging Python libraries, identifying security vulnerabilities, and training complex image recognition models. These aren't simple, repetitive tasks. They require sustained reasoning and problem-solving that would challenge human developers.

⬤ Why does this matter outside the AI research community? Think about what becomes possible when an AI can reliably work for multiple hours without human babysitting. Extended coding sessions, continuous research workflows, complex data analysis—all without constant intervention or resets. As models like Claude Opus 4.5 push past the five-hour mark, we're watching endurance become just as important as accuracy in determining which AI systems will actually be useful for real-world applications. The chart makes it clear: we're not just getting smarter AI, we're getting AI that can sustain that intelligence long enough to actually finish difficult jobs.
 Marina Lyubimova
Marina Lyubimova


