 Artem Voloskovets
Artem Voloskovets

⬤ Fresh benchmark results from EpochAI's FrontierMath tests show a clear performance gap between top-tier frontier language models and China's best open-weight alternatives. The data tracks accuracy across FrontierMath Tiers 1 through 3, revealing that Chinese open-weight systems are lagging about seven months behind in overall capability. As the difficulty level increases, this gap becomes even more obvious, suggesting it's not just a temporary setback but a consistent pattern.
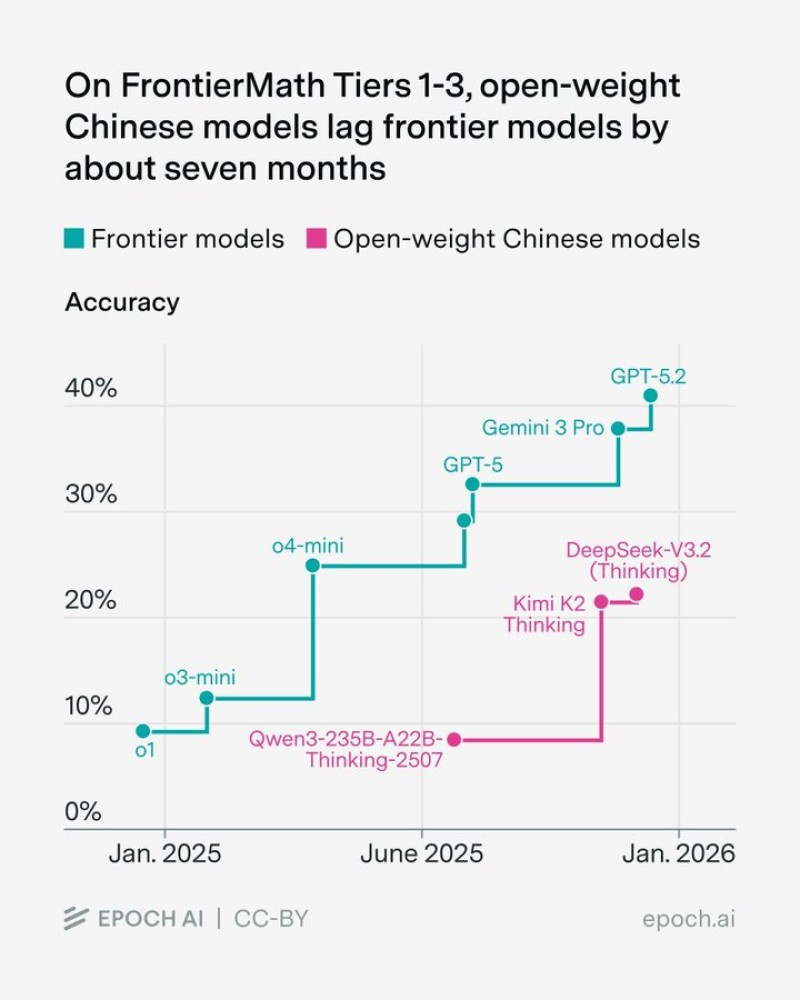
⬤ Frontier models like GPT-5, Gemini 3 Pro, and GPT-5.2 show faster improvement rates and hit higher accuracy marks earlier in the timeline. Meanwhile, Chinese models including Qwen and Kimi variants progress more slowly, staying grouped at lower performance levels during the same testing periods. The charts paint a picture of two different development speeds rather than a complete standstill for either group.
⬤ The real eye-opener comes with FrontierMath Tier 4, the toughest mathematical reasoning challenge in the set. Among Chinese open-weight models, only DeepSeek-V3.2 in "Thinking" mode managed to solve anything at all—just 1 problem out of 48, landing at roughly 2 percent accuracy. Compare that to GPT-5 Pro, which leads the pack by solving 6 out of 48 problems for about 13 percent accuracy, with Gemini 2.5 Deep Think right behind at approximately 12 percent with 5 problems solved.
⬤ These findings carry weight because they point to genuine capability differences in complex mathematical reasoning, not just quirks of a single test. Since advanced math performance often serves as a stand-in for deeper analytical thinking, FrontierMath results could shape how researchers and organizations judge whether models are ready for demanding real-world tasks and next-generation AI development.
 Artem Voloskovets
Artem Voloskovets


