 Peter Smith
Peter Smith

⬤ Anthropic just dropped benchmark results for Claude Opus 4.5, and the numbers tell a pretty impressive story. The new model doesn't just top the charts across multiple benchmarks—it actually flips the script on what we've come to expect from the Opus line. According to WeirdML benchmark data, Opus 4.5 hit the highest accuracy scores among all Claude models tested on fresh datasets, which is a big deal considering earlier Opus versions consistently trailed behind the Sonnet models.
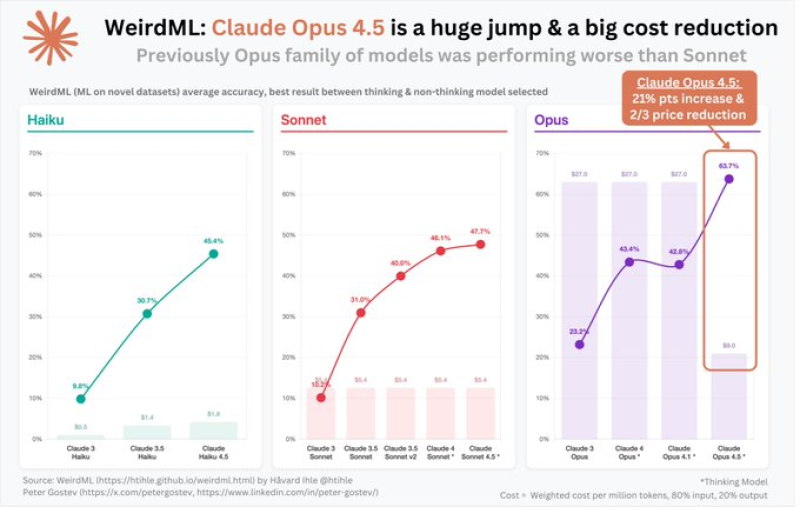
⬤ The performance leap is hard to ignore. Opus 4.5 shows roughly a 21 percentage point accuracy boost compared to its predecessors, while simultaneously cutting costs by about two-thirds per million tokens. For a model family that's historically struggled to keep pace with Sonnet in both efficiency and raw performance, this represents a complete turnaround in strategy and execution.
⬤ What's driving these gains? The focus seems to be on specialized training for code generation, agent workflows, and tool integration. As one researcher noted, "The magnitude of the jump between Opus 4.0, 4.1, and 4.5 indicates more than incremental tuning—we're looking at deeper changes in model development or training strategy." This targeted approach to specific use cases, rather than broad general improvement, appears to be paying off in measurable ways.
⬤ Perhaps the most interesting takeaway is how dramatically Opus 4.5 diverges from earlier Opus models. The performance gap between Opus and Sonnet has essentially reversed, showing just how quickly the competitive landscape can shift in AI development. For teams building software tools or agent-based systems, these benchmark results suggest Opus 4.5 might finally offer the combination of capability and cost-effectiveness that previous versions couldn't quite deliver.
 Peter Smith
Peter Smith


