 Usman Salis
Usman Salis

● In a recent tweet from Chubby, confirmed by Verdent, Verdent reached a new benchmark — 76.1% on first attempt and 81.2% after three tries on SWE-Bench Verified. This test is one of the toughest for AI coding systems, checking if they can spot and fix real bugs without help.
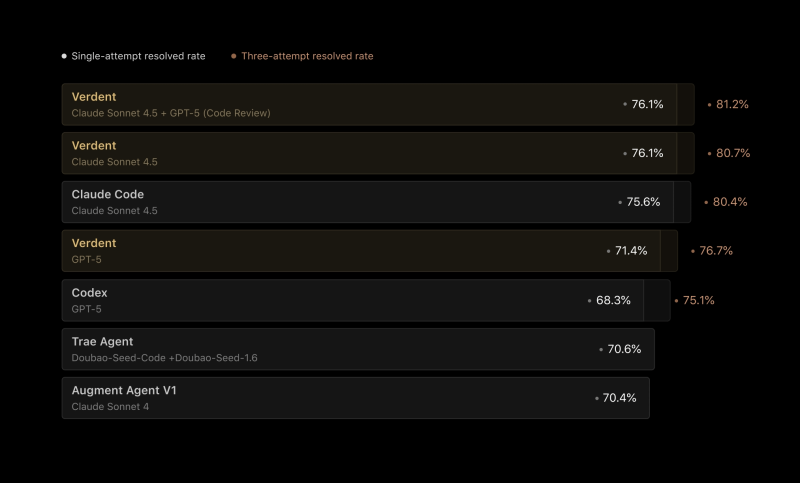
● Verdent said the test ran "using the same setup our users have in production," showing they care more about reliability than just topping leaderboards. Unlike many AI models tuned just for tests, Verdent's scores reflect how it actually performs in real development work.
● Verdent uses multiple models working together — Claude Sonnet 4.5 handles reasoning and planning, while GPT-5 checks the code. One model thinks through the problem, the other validates the fix. This cuts down errors and boosts efficiency.
● The real win here? Closing the gap between flashy demos and tools you can trust in production. Verdent's verification process runs tests before anything ships, stopping "hallucinated fixes" — those nonsense solutions AI sometimes generates. Features like Plan Mode, DiffLens, and Sub-Agents make debugging clearer and give developers more control across messy codebases.
● For the industry, this matters. Verdent's results point toward AI systems that are reproducible and auditable — the kind you need for regulated environments and enterprise use.
● As the original post says, "Verdent delivers real-world robustness through multi-model orchestration, verification-first pipelines, and reproducible code." This benchmark proves a bigger shift: AI is moving from just scaling up models to building systems that are tested, transparent, and actually reliable.
 Usman Salis
Usman Salis


