 Saad Ullah
Saad Ullah

⬤ A recent coding experiment put several top AI models to the test by asking them to write the same function in eight different indentation styles. The visual breakdown shows the exact formatting patterns tested—Allman, Kernighan & Ritchie, GNU, Whitesmiths, Horstmann, Haskell, Ratliff, and Lisp styles—making it easy to compare how each model performed.
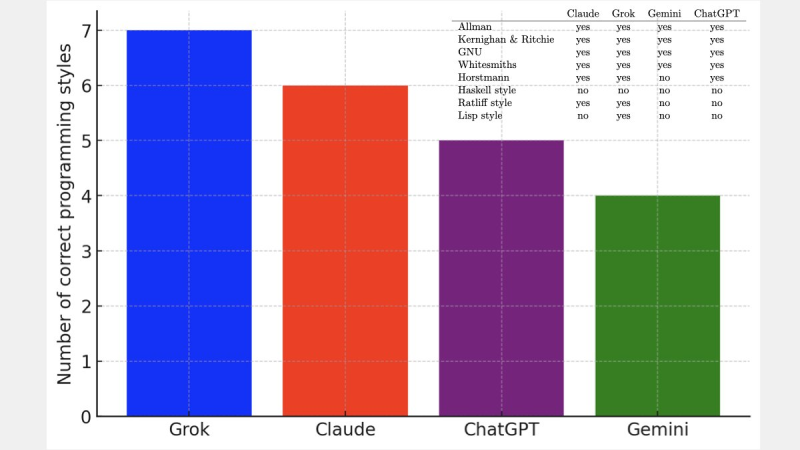
⬤ Interestingly, all models struggled with Haskell style, getting it wrong across the board. Beyond that universal hiccup, the results varied quite a bit. Grok led the pack with seven correct styles, Claude managed six, ChatGPT hit five, and Gemini scored four. These numbers line up perfectly with the bar chart showing each model's accuracy.

⬤ While this test focused purely on formatting rather than complex logic, it points to a real concern for companies using AI in their development workflows. When models differ so much in following strict style guidelines, teams might end up dealing with more debugging, inconsistent code, or workflow hiccups. In environments where coding precision matters for security, reliability, or compliance, these gaps could mean extra work and resources spent fixing AI-generated code—similar to other operational costs businesses face in regulated fields.
⬤ That said, the experiment offers useful insights. Grok's ability to nail seven out of eight programming styles shows it's better at sticking to formatting rules than its competitors. For developers and teams weighing their AI options, it's clear that raw intelligence isn't everything. Getting small but crucial details right—like indentation—can make a big difference in productivity, code quality, and how much you can trust your AI coding assistant.
 Saad Ullah
Saad Ullah


