 Saad Ullah
Saad Ullah

⬤ Nvidia just rolled out Nemotron-Cascade, a fresh take on scaling reinforcement learning for general-purpose reasoning models. Instead of throwing everything into one giant training phase, the framework breaks things down into cascading, domain-specific stages—think of it as teaching the model one skill at a time rather than everything at once. Nemotron-Cascade runs sequential reinforcement learning across different domains, which makes the whole training process more stable and efficient.
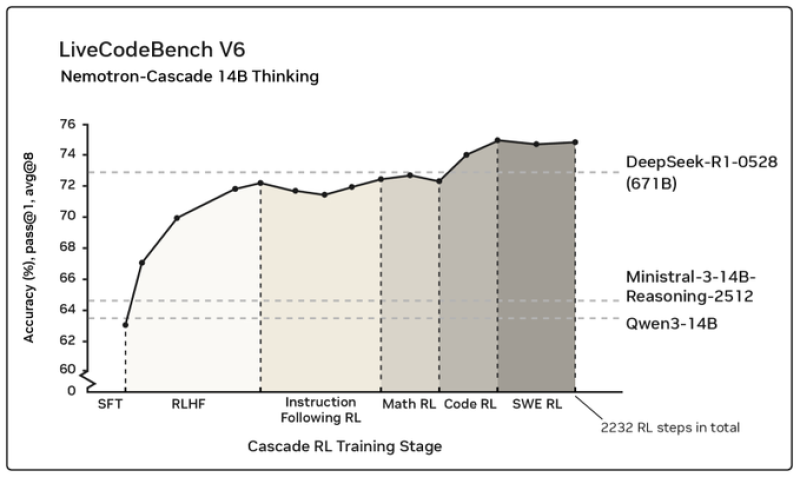
⬤ The LiveCodeBench V6 results paint a pretty clear picture of how this approach pays off. The Nemotron-Cascade 14B Thinking model starts with supervised fine-tuning and then moves through reinforcement learning with human feedback, instruction-following RL, math-focused RL, code RL, and software engineering RL. The data shows average pass accuracy climbing from around 60% in the early stages to roughly 75% by the final cascade stage after 2,232 reinforcement learning steps.
⬤ The benchmark visualization includes reference points from other reasoning models like DeepSeek-R1-0528, Qwen3-14B, and Mistral-3-14B-Reasoning-2512, giving context to where Nemotron-Cascade lands. What stands out is how the cascading approach delivers consistent gains without sudden drops or erratic behavior—suggesting that training structure might matter just as much as raw model size.

⬤ Reasoning capability is quickly becoming the measuring stick for advanced AI systems, especially when you're dealing with coding, mathematics, and software engineering tasks. More stable reinforcement learning pipelines mean better consistency across complex workloads and less training volatility. Nemotron-Cascade points to where AI development is heading—toward staged optimization strategies where how you train a model is becoming just as critical as how big you make it.
 Saad Ullah
Saad Ullah


