 Eseandre Mordi
Eseandre Mordi

⬤ Microsoft just dropped Agent Lightning, an open source framework that solves a problem developers have been wrestling with for years—how to add reinforcement learning to AI agents without ripping apart your entire codebase. The framework lets you plug RL directly into whatever agent workflow you're already running. At its heart is a centralized orchestration layer that connects inference engines, LLM proxies, and training components without forcing them to talk directly to each other.
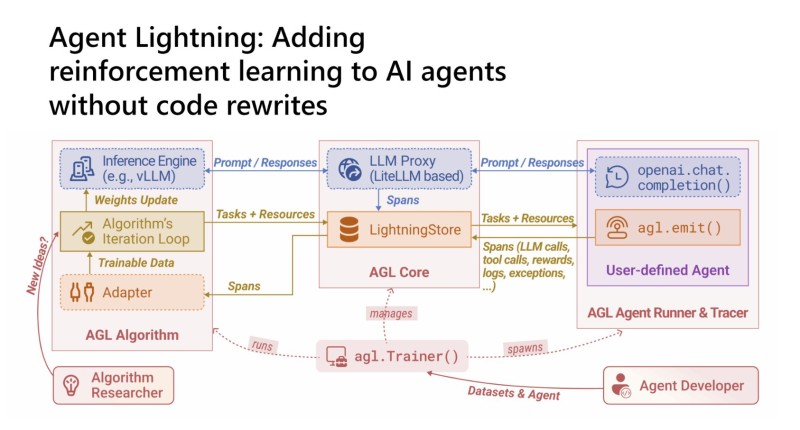
⬤ What makes Agent Lightning work is its modular setup—agent execution and training run completely separately. Inference engines like vLLM handle the day-to-day agent work while everything that happens gets tracked and dumped into LightningStore. Every LLM call, tool usage, reward signal, log entry, and error gets captured as training data. The training loop picks up these traces and runs RL algorithms on them while your agents keep doing their thing uninterrupted.
⬤ The framework comes with battle-tested RL algorithms including PPO and GRPO built in, and it's designed to handle complex scenarios—multi-step reasoning, tool-using agents, even multi-agent systems. Here's where it gets interesting: agents can run efficiently on CPUs while the heavy RL training scales independently on GPUs. The AGL Core acts as mission control, managing task coordination, collecting activity spans, and directing data between agent runners and the training process.

⬤ Agent Lightning tackles a real pain point in production AI systems. Until now, adding reinforcement learning meant weeks of engineering work and tightly coupling your training logic with execution code. Microsoft's approach turns existing agent workflows into RL-ready data streams without the headache. You can now iterate and experiment with self-improving AI agents that learn from experience—no system rebuild required.
 Eseandre Mordi
Eseandre Mordi


