 Saad Ullah
Saad Ullah

⬤ KlingAvatar 2.0 just dropped on Hugging Face with a fresh take on making AI avatar videos. Instead of doing everything at once, it breaks the job into three separate stages: planning what happens, building the motion structure, and polishing the final visuals. The new setup uses multimodal instruction fusion to give creators better control while keeping things efficient.
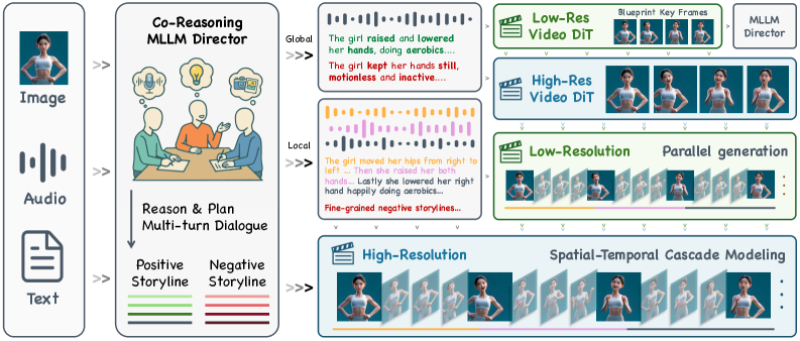
⬤ The system starts by feeding images, audio, and text into something called a Co-Reasoning MLLM Director. This module thinks through the video creation process multiple times, mapping out both what should happen and what to avoid before any actual video gets made. Then it moves to a low-resolution stage where a Video DiT model sketches out the basic movements and timing. Blueprint keyframes keep everything looking consistent from start to finish.
⬤ Once the foundation's solid, KlingAvatar 2.0 kicks into high-res mode through a second Video DiT pipeline. The spatial-temporal cascade approach means it can add fine details gradually without breaking the flow between frames. Lower-resolution work happens in parallel to speed things up, while the high-res stage focuses purely on making everything look crisp. The architecture also lets local and global reasoning work together, which means tighter control over gestures, movements, and timing.
⬤ This release marks a real shift in how AI video tools are built. Most avatar generators struggle with staying consistent over long videos and eat up tons of computing power doing it. KlingAvatar 2.0's modular approach—splitting reasoning, low-res planning, and high-res finishing into distinct steps—could become the blueprint for next-gen video systems, especially ones that need sustained realism and precise control across multiple input types.
 Saad Ullah
Saad Ullah


