 Alex Dudov
Alex Dudov

⬤ Epoch AI just dropped some eye-opening research that maps out when we might actually run out of public human text for training AI models. The numbers are pretty stark – we're looking at a potential "data wall" hitting within just a few years as AI training appetites keep growing way faster than the amount of text available online.
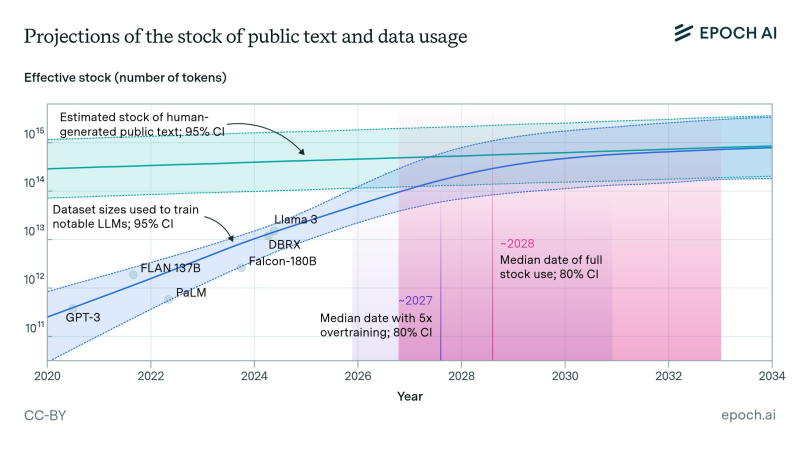
⬤ Here's what the data shows: Epoch AI compared the total stock of public human-generated text (with a 95% confidence interval) against the dataset sizes used for major AI models like GPT-3, PaLM, FLAN-137B, Falcon-180B, DBRX, and Llama 3. The trend line for dataset sizes is climbing sharply toward that public-text supply ceiling. They're projecting we'll hit "5× overtraining" around 2027 and completely tap out the public text stock by 2028 (with 80% confidence). Bottom line? All that publicly available human language data might get completely absorbed into AI training pipelines unless companies find new approaches or data sources.
⬤ What does this mean for AI scaling strategies? The research suggests that unless fresh training data sources open up, continued expansion of model sizes could hit a serious roadblock. While the data doesn't make specific market predictions, it's clear that dataset sizes have been growing at a much faster rate than the actual supply of human-generated text available for training.

⬤ Why should you care about this? We're potentially looking at a hard ceiling on AI development right when demand for model training is accelerating. Once that usable pool of public text hits capacity, AI developers will need to pivot – whether that means licensing more content, generating synthetic data, tapping private datasets, or developing entirely new learning methods. Any of these shifts could significantly reshape how quickly AI models advance and what direction they take next.
 Alex Dudov
Alex Dudov


