 Peter Smith
Peter Smith

⬤ Context engineering is becoming a fundamental skill in how large language models are built and deployed across the AI landscape. Many developers still see retrieval-augmented generation as just pulling documents into prompts, but the new framework shows it's really about designing how AI systems get the right information at exactly the right moment—without touching the underlying model itself. This discipline creates the essential connection between AI models and the external data and tools they depend on.
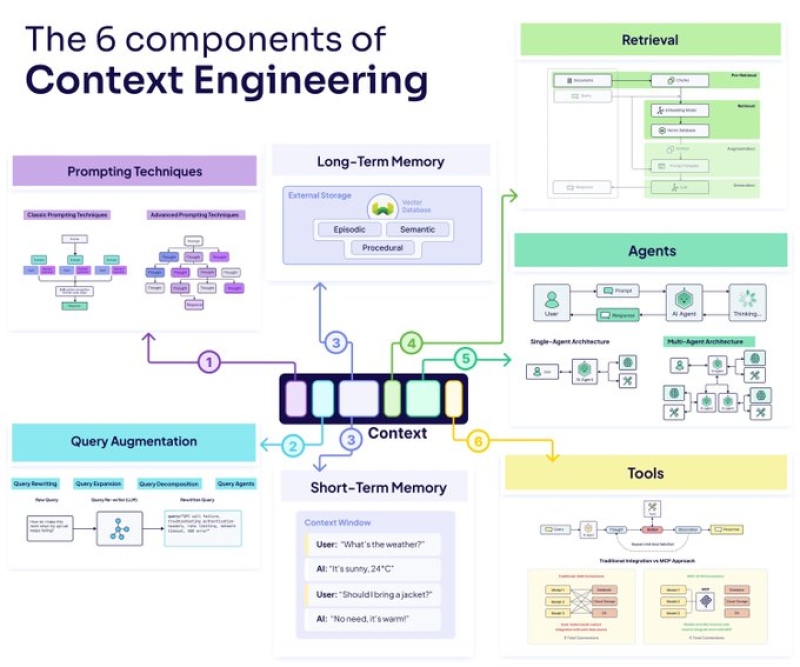
⬤ Six core components shape effective AI context design: query augmentation, retrieval, memory, agents, tools, and prompting. Query preparation—like rewriting, expanding, or breaking down requests—lays the groundwork for everything that follows. How you chunk and process data during retrieval determines what information actually makes it to the model. Memory splits into two types: short-term working context and long-term storage using vector databases and episodic archives, both influencing how the system thinks and responds.
⬤ Agents act as coordination layers, managing how AI systems interact with APIs, databases, and search functions when handling user requests. Different prompting techniques—from basic instructions to tool-specific patterns—change how models process the context they receive. The framework addresses real challenges like context window limitations, data overlap confusion, and "context clash," backed by practical diagrams and architecture examples.

⬤ This matters because AI performance now depends more on how information gets organized, routed, and managed than just model size alone. As companies across industries adopt AI at scale, context engineering is shaping product reliability, accuracy, and user experience—making it a critical area for investment and skill development in enterprise AI strategies.
 Peter Smith
Peter Smith


