 Saad Ullah
Saad Ullah

⬤ Here's the thing: a new diagnostic study from the Koita Centre for Digital Health at Ashoka just put leading AI systems head-to-head with medical professionals in a radiology benchmark. The evaluation tested board-certified radiologists, radiology trainees, and several major AI models including Gemini 3.0 Pro, GPT-5 thinking, Gemini 2.5 Pro, OpenAI o3, Grok 4, and Claude Opus 4.1. The results paint a pretty clear picture of where human expertise stands against current AI capabilities.
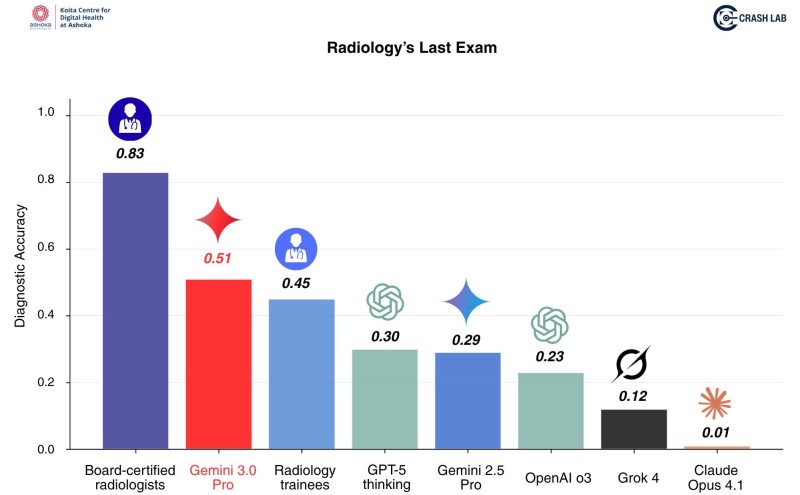
⬤ Let's be real about the numbers. Board-certified radiologists crushed it with an accuracy score of 0.83, leaving everyone else in the dust. Gemini 3.0 Pro came in as the top AI performer at 0.51, while radiology trainees landed at 0.45. The other AI systems? They're still playing catch-up: GPT-5 thinking hit 0.30, Gemini 2.5 Pro managed 0.29, and OpenAI o3 scored 0.23. Grok 4 and Claude Opus 4.1 brought up the rear with disappointing scores of 0.12 and 0.01. These numbers show both how far medical AI has come and how much ground it still needs to cover in precision diagnostic work.
⬤ The benchmark reveals something interesting: AI performance across radiology is all over the map, and none of the tested systems even came close to matching human-level accuracy. What's striking is how the visual data places every single AI result well below the radiologist benchmark, really driving home that we're still in the early innings of AI's medical capabilities. That said, Gemini 3.0 Pro's performance does suggest things are moving fast, significantly outpacing earlier-generation systems.
⬤ Why does this matter? Companies building medical AI tools are staring down some serious accuracy gaps before their systems can reliably assist with or automate high-stakes clinical decisions. This benchmark captures both the massive opportunity in healthcare AI and the very real challenges that need solving before these systems can become truly dependable in diagnostic settings.
 Saad Ullah
Saad Ullah


