 Marina Lyubimova
Marina Lyubimova

⬤ OpenAI's GPT-5.2-Codex is getting a closer look after fresh session data exposed just how big the speed gap is between its reasoning modes. Personal logs were crunched to figure out average and median response times for both medium and extra-high reasoning, and the numbers tell a pretty clear story—medium mode wins on speed by a mile.
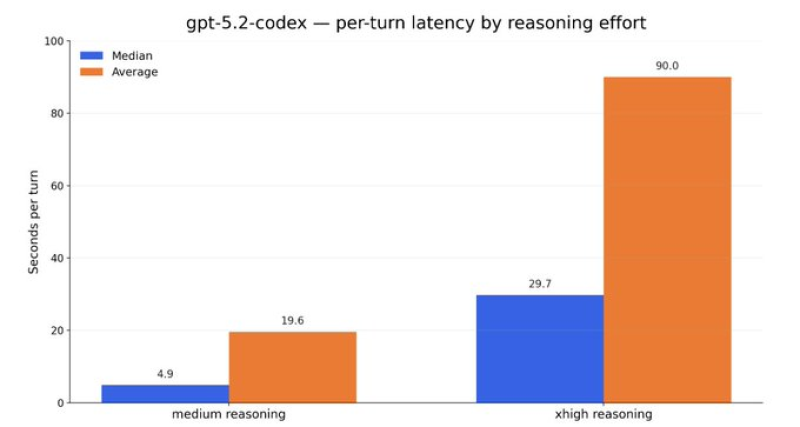
⬤ The breakdown shows GPT-5.2-Codex hitting a median of 4.9 seconds per turn with medium reasoning, while extra-high reasoning clocked in at 29.7 seconds. When you look at averages, the gap gets even wider: 19.6 seconds for medium versus 90.0 seconds for extra-high. That means medium mode runs about four to five times faster on average, with extra-high reasoning racking up way more slow responses.
⬤ The takeaway here is pretty straightforward—medium reasoning makes sense as the go-to setting for most tasks, while extra-high reasoning is better saved for jobs where you've got time to spare, like background processes. The data doesn't dig into output quality, but it does highlight the classic trade-off: more reasoning power costs you more wait time, which can really slow things down in workflows that need quick back-and-forth.
⬤ These speed differences matter because they directly shape how GPT-5.2-Codex gets used day-to-day, whether that's in productivity apps, research projects, or full-scale enterprise setups. As AI keeps getting more capable and complex, figuring out the right balance between speed, efficiency, and reasoning depth becomes key to picking the right mode and keeping the user experience smooth.
 Marina Lyubimova
Marina Lyubimova


