 Peter Smith
Peter Smith

● Epoch AI just dropped its updated Capabilities Index, and the takeaway is crystal clear: throw more compute at AI training, and you get smarter models. The Index pulls together public benchmark results from the big players—OpenAI, Anthropic, Google, xAI, and Meta—and reveals an exponential relationship between computational power and model intelligence across systems that vary by up to 100,000× in compute resources.
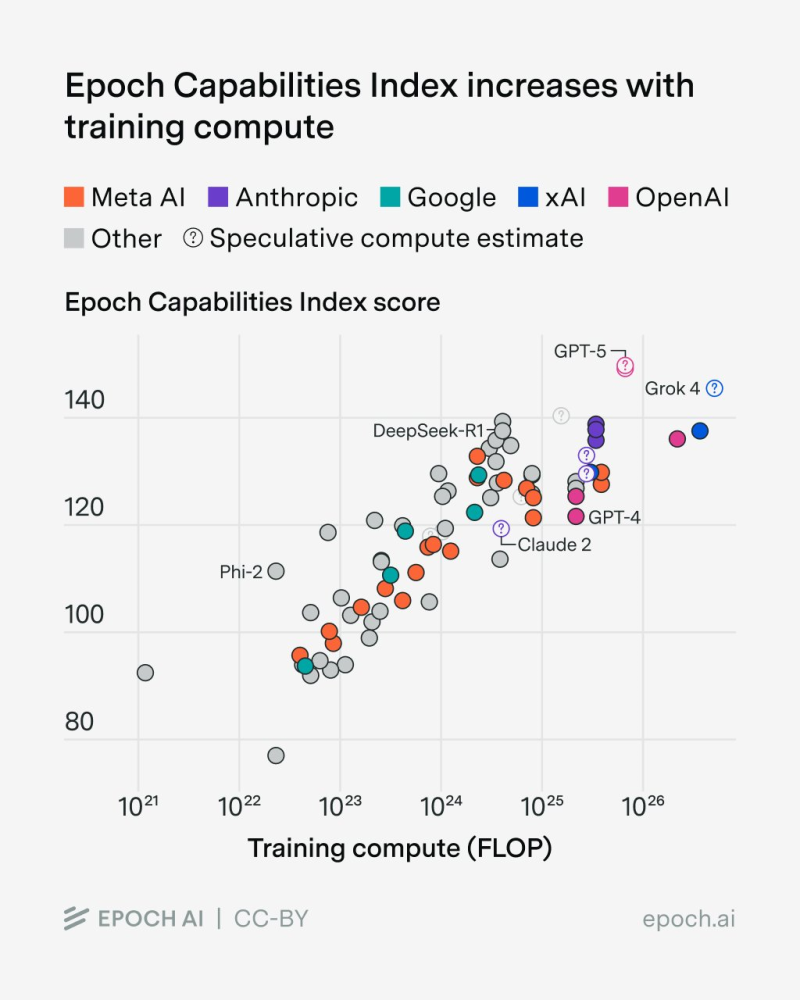
● Models trained with over 10²⁵ FLOPs—think GPT-5, Grok 4, Claude 2, and DeepSeek-R1—score highest across reasoning, coding, and multimodal tests. But there's a catch: training costs are now reaching hundreds of millions per model, compute demand is stressing global infrastructure, and the AI race risks becoming a game only a few tech giants can afford to play.
● As costs skyrocket, researchers are hunting for smarter alternatives. Epoch AI points out that performance gains start to plateau beyond certain compute thresholds, suggesting future breakthroughs might come from algorithmic improvements, better data selection, and hybrid designs rather than just piling on more GPUs. This could signal a shift from massive hardware expansion to more intelligent resource optimization.
● The Index also exposes a widening gap between well-funded frontier labs and open-source projects. While GPT-5 and Grok 4 dominate overall, models like Claude 2 and Gemini 2.5 prove you can still compete with efficiency-focused approaches at lower compute scales. Epoch's work offers some of the strongest evidence yet for AI scaling laws—more compute means smarter systems, but at a growing economic and environmental price tag.
 Peter Smith
Peter Smith


