 Usman Salis
Usman Salis

⬤ Chinese AI researchers have rolled out a new research framework called the Agentic Learning Ecosystem (ALE), paired with a model known as ROME. The framework targets major gaps in how today's AI agents are trained and put to work. The research describes current AI-agent infrastructure as largely "broken" and presents ALE as a full-stack ecosystem that supports a closed-loop workflow: task → action → execution → feedback → learning.
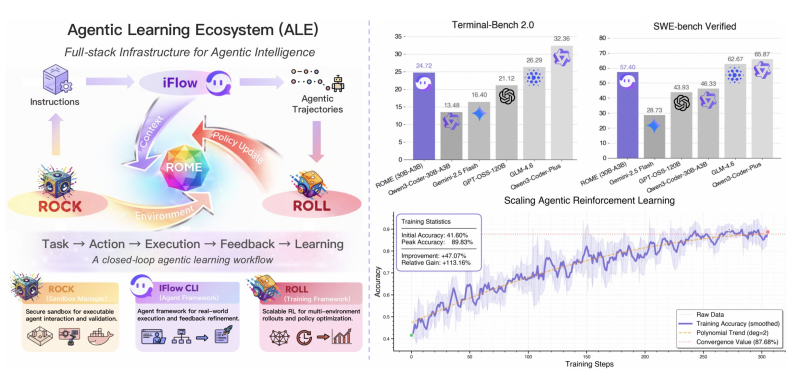
⬤ ALE is built around three core system components. ROCK serves as a secure sandbox where agents can interact and validate their actions safely. iFlow acts as the agent framework managing real-world execution and refining feedback. ROLL provides a reinforcement-learning framework that handles multi-environment rollouts and policy optimization. At the heart of this loop is the ROME model, which updates policies based on environment feedback to drive continuous performance improvement.
⬤ Benchmark results show ROME (30B-A3B) hitting a score of 57.40 on SWE-Bench Verified and 24.72 on Terminal-Bench 2.0—outperforming models like GPT-OSS-120B, Gemini-2.5 Flash, GLM-4.6, and Qwen3-Coder-Plus. Training data reveals accuracy jumped from 41.60% to a peak of 89.83%—a 47.07-point gain and 113.16% relative improvement—before stabilizing around 87.68%. These numbers highlight the scaling potential of agentic reinforcement learning within the ALE-ROME pipeline.

⬤ This release marks a shift from static prompt-response AI systems toward structured, continuous learning driven by real-world feedback loops. As the focus moves to AI agents capable of autonomous task execution, frameworks like ALE and ROME could shape how next-generation agent intelligence is trained, evaluated, and deployed across complex tasks and environments.
 Usman Salis
Usman Salis


