 Peter Smith
Peter Smith

⬤ Nvidia's GB200 NVL72 platform is emerging as a cost-efficiency powerhouse in AI infrastructure based on new benchmark comparisons. The data zeroes in on what really matters in the AI economy: how much you actually pay for the intelligence you get. The comparison pits Nvidia's GB200 NVL72 against the MI355X platform across two user interaction speeds—25 tokens per second and 75 tokens per second.
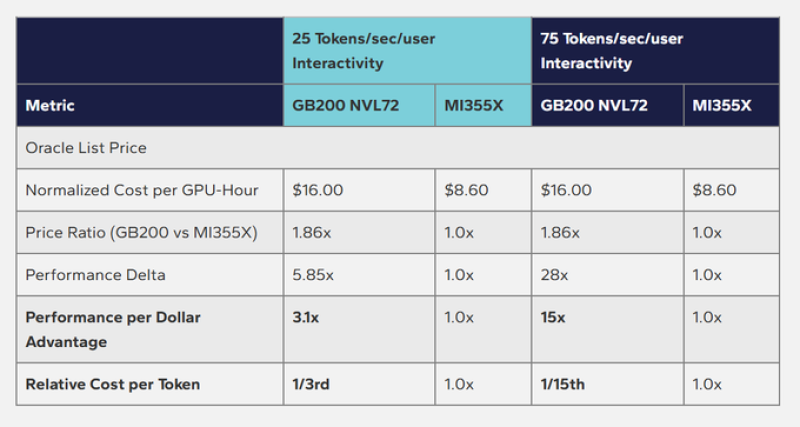
⬤ Here's where it gets interesting: while the GB200 costs more per GPU-hour at $16.00 versus MI355X's $8.60, it absolutely crushes the competition on performance. At 25 tokens per second, the GB200 delivers 5.85× better performance, which translates to 3.1× more bang for your buck and costs just one-third as much per token. Crank it up to 75 tokens per second, and the gap becomes massive—28× performance advantage, 15× better value per dollar, and a cost per token that's one-fifteenth of what you'd pay with MI355X.
⬤ The price gap stays consistent at 1.86× across both speeds, meaning yes, Nvidia hardware costs more upfront on a per-hour basis. But that higher price buys you dramatically more actual throughput. When you factor in faster response times, the ability to handle way more users at once, and running complex AI models without frustrating delays, that premium starts looking like a bargain. That's where the GB200 NVL72 really separates itself from the pack.
⬤ These numbers show why cost per token and performance per dollar are becoming the metrics that actually matter in AI computing. For Nvidia, the GB200 NVL72 benchmarks make it crystal clear why performance scaling is reshaping how people think about value in AI infrastructure. The focus on throughput, speed, and cost efficiency reflects a fundamental shift—AI hardware decisions are now driven by what you can actually do with the system, not just what the price tag says.
 Peter Smith
Peter Smith


