 Victoria Bazir
Victoria Bazir

⬤ Artificial Analysis dropped fresh benchmark data showing KAT-Coder-Pro V1 sitting at the top of non-reasoning models on its Intelligence Index. The model locked in a score of 64, beating every other system that doesn't use chain-of-thought or internal reasoning processes. The charts put it right next to heavy hitters like Grok 4.1 Fast and Claude Sonnet 4.5, proving it can hang with the big names despite working through a completely different approach.
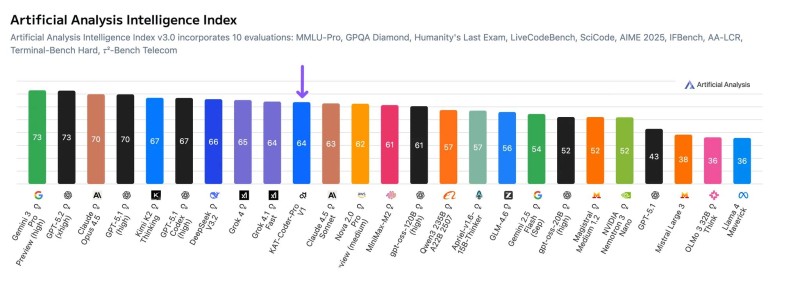
⬤ KAT-Coder-Pro V1 crushed several benchmarks usually dominated by reasoning models. It pulled 89% on Tau2-Telecom (which tests agentic tool use), landed 33% on Humanity's Last Exam, and scored 74% on AA-LCR for long-context reasoning. Sure, it bombed CritPT—a frontier physics test—with 0%, but the overall performance shows you don't need explicit reasoning outputs to compete at this level.
⬤ The real story here is token efficiency. KAT-Coder-Pro V1 only generated about 7.6 million output tokens—dramatically less than comparable models hitting similar scores. Grok 4.1 Fast burned through roughly 71 million tokens, while Claude Sonnet 4.5 used around 42 million. The model also scored -36 on the Omniscience Index, beating GPT-5.1 in the non-reasoning bracket and Gemini 2.5 Flash, with 18% accuracy and 66% hallucination rate.
⬤ These numbers point to a split in how developers are building large language models. Output efficiency and simpler architecture are proving they can compete with explicit reasoning chains. KAT-Coder-Pro V1 runs with a 256K token context window, handles text-only input and output, and works through API access—showing non-reasoning models can stay competitive at the top tier while cutting computational costs. As benchmarking keeps evolving, the Artificial Analysis Intelligence Index keeps giving us clearer comparisons across performance, efficiency, and how well these different approaches actually scale.
 Victoria Bazir
Victoria Bazir


