 Saad Ullah
Saad Ullah
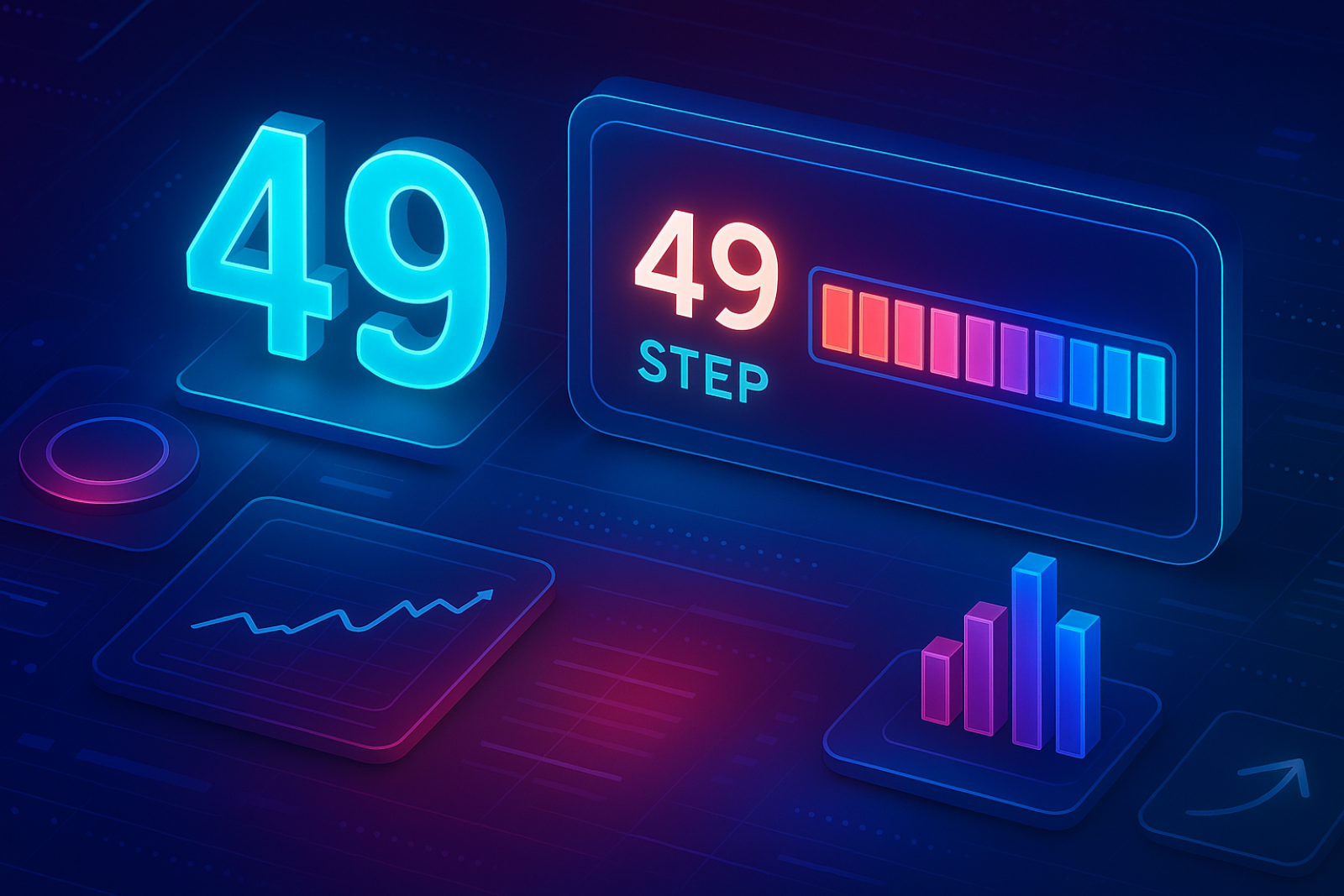
⬤ Jan dropped Jan-v2-VL, a serious upgrade to its multimodal AI agent built for handling lengthy task chains. The new system runs on the Qwen3-VL-8B-Thinking base model and brings massive stability improvements and how deeply it can think through problems. Jan-v2-VL can knock out 49 sequential steps without messing up, while the old base model only managed 5 steps, and other vision-language models in the same weight class typically handle just 1 to 2 steps. The whole thing runs right in your browser while staying accurate.
⬤ Jan designed Jan-v2-VL specifically for long sequences that need structured reasoning, visual understanding, and chained task execution. They're releasing three versions: Jan-v2-VL-low for speed, Jan-v2-VL-med for a balance between performance and efficiency, and Jan-v2-VL-high for the deepest reasoning and longest execution chains. You can grab the new models from Hugging Face Model Hub after updating the Jan App, with Browser MCP servers powering the full agentic features. That jump from 5 steps to 49 really shows how much tougher this model is when dealing with complex workflows.
Jan-v2-VL can complete 49 sequential steps without failure, compared with only 5 steps handled by the previous base model.
⬤ The team gave props to Alibaba's Qwen crew for the Qwen3-VL-8B-Thinking architecture that powers everything. The benchmark results show Jan-v2-VL keeps its cool over extended runs without losing accuracy—something other models in this parameter class have struggled with. Strong multimodal input support and long-horizon planning make this update one of the most advanced browser-based agents you can get right now.
⬤ This Jan-v2-VL release matters because better long-horizon execution directly impacts how useful AI agents are for productivity apps, development work, and automated digital workflows. More reliable step-by-step reasoning means agents can handle more tasks on their own, with fewer interruptions and better real-world deployment potential. With 49-step execution without failures, Jan-v2-VL just set a new performance bar in the fast-moving multimodal agent space.
 Saad Ullah
Saad Ullah


